Last month, we visited Addis Ababa to hold a workshop for the Ethiopic Script Generation Panel. Upon arriving, while being introduced to the rich history and culture of Ethiopia, we were told that coffee beans originated from Kaffa, which was a medieval kingdom in ancient Ethiopia. The beans grow from a shrub called bun in Oromo, a language of the region. Already charmed with this discovery, our interactions began with a visit to the Institute of Ethiopic Studies (IES), which is home to a museum that took us on a journey through the beautiful and diverse heritage of Ethiopia. The museum was a perfect first stop for our trip, as it gave us a better understanding of the complex task ahead.
Following the museum, we visited the Academy of Ethiopic Languages and Cultures (AELC) within the Addis Ababa University campus. There, professor Mulugeta Seyoum enthusiastically discussed their active involvement in studying languages, philology, lexicography and the culture of Ethiopia. With 91 languages spoken in Ethiopia, they have their work cut out for them.
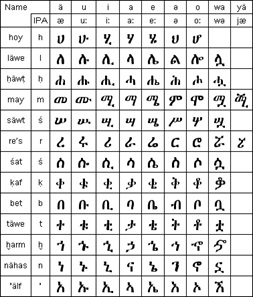
Image acquired from omniglot
As the professor showed us the academy's numerous publications, including the lexicons published for various languages like Amharic, Kebena, Oromo and Tigrinya, he educated us on the academy's ongoing efforts to develop orthography for many of the oral languages being spoken in the country, such as Komo, a lesser known Nilo-Saharan language. He explained how the current use of Ethiopic script differs from its use for Ge'ez, which originated in the 5th century BCE. He explained that the script is an alphasyllabary, with each character in the script denoting a combination of a consonant and a vowel. He noted how this consonant-vowel structure makes it hard for them to transcribe double consonant-consonant sequences (called geminates). These geminates are as native for the languages they are working on as their sourdough bread made from teff (with a geminated 'f'). We found his enthusiasm as invigorating as the brewed cup of coffee we enjoyed with him at the make-shift university canteen. As we drank this locally grown coffee, we silently wondered how they would spell Kaffa in Ethiopic script, which also has a geminate.
Some of the researchers at AELC are part of the Ethiopic Generation Panel (GP), trying to solve a very different problem – developing Ethiopic script Label Generation Rules (LGR) for the root zone. These researchers bring unmatched expertise to this difficult task, as they collaborate with the technical members of the panel, which is led by Professor Dessalegn Mequanint from the Computer Science Department of the Addis Ababa University. The panel also includes members from telecommunications, government and private sectors.

The goal of our 21-23 July trip to Addis Ababa was to train this expert group on the details of the procedure to develop the root zone LGR [PDF, 1.4 MB] defined by the community. The training was organized through the Internationalized Domain Name (IDN) Program and the Global Stakeholder Engagement (GSE) Africa team to "Institutionalize IDN Support". This strategic project, is part of ICANN's overall Africa Strategy, which was launched in 2013 and revised in Mauritius in November 2015, for the period ending in 2020.
This is the second training of its kind in Africa, following the first one in Pointe-Noire, Congo last year. These workshops are designed to foster active participation from experts in Africa in the various projects related to African languages and scripts - not just in the Ethiopic script panel. Our trip to Ethiopia also gave us a unique opportunity to invite participants from Africa to join the Latin script panel, as there are many African languages which are written in the script, such as, Éwé, Kinyarwanda, Hausa and others.
There are many other script communities which have organized themselves to contribute to the LGR for the root zone. These efforts are at various stages in their work, as illustrated by the chart below.
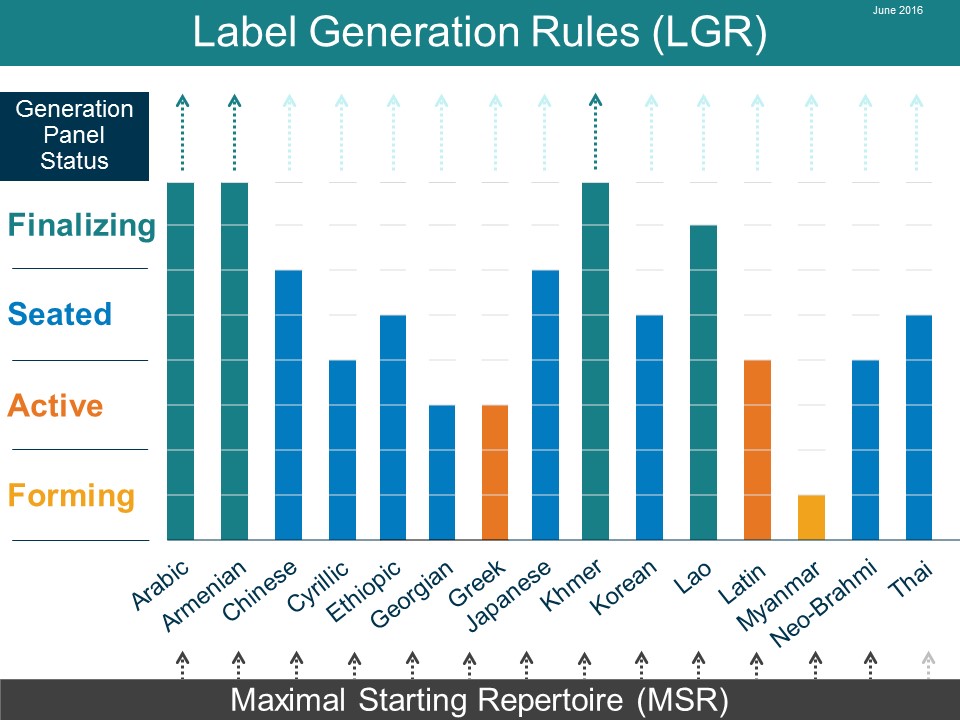
We are grateful to the African Union Commission and the Computer Science Department at the Addis-Ababa University for facilitating and hosting this workshop. As part of ICANN's Africa Strategy, our engagement with the community in Africa will continue to expand in the future.
If you are interested in volunteering for any of these scripts or starting work on another script which you use, please send an email to [email protected].

