Earlier this week, we inserted eleven new top-level domains in the DNS root zone. These represent the term “test” translated into ten languages, in ten different scripts (Chinese is represented in two different scripts, and Arabic script is used by two different languages).
This blog post is not about that. (If you’re interested about it, read our report on the delegations.)
What I would like to talk about is some of the difficulties we face today in expressing scripts in a consistent way over the Internet. The fact is, whilst we are at the best time in history for having computers represent many different languages clearly and consistently, we are still a long way from the level of support needed to give us strong confidence that people can always see what we intend them to see.
To illustrate, I will list all the eleven new top-level domains. On the left is the version your web browser wants to present to you, and on the right is how it should actually look.
| إختبار | ||
| آزمایشی | ||
| 测试 | ||
| 測試 | ||
| испытание | ||
| परीक्षा | ||
| δοκιμή | ||
| 테스트 | ||
| טעסט | ||
| テスト | ||
| பரிட்சை |
If you find some of the versions don’t match, you would be in the majority of Internet users. The fact is most people cannot see these labels properly and consistently.The most likely problem you will face is that there will be some labels that you simply cannot see, because your computer does not have any font that can express the characters. When the correct font can not be found it will usually display something like the following:
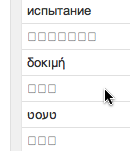
Computers never come with the complete set of fonts that will allow it to show every possible IDN in the world. The primary concern is to supply fonts that allow the language used on the computer to work, and the rest are optional. Often this is fixed by downloading additional language packs for the missing languages, or specifically finding and installing fonts that support the wanted languages.
Finding fonts is sometimes only half the battle. English, on the scale of languages, is one of the simplest to represent by computer. It has 26 letters, and they always look the same and are presented the same no matter what order they are in. Sure, they may be stylistic variants, but in terms of composing letters it is very simple.
Take a look at this:

On the left is the correct way to present this, but those of you that do have Arabic fonts may find that you see the version on the right. This is because Arabic has more complex rules on how letterforms should be connected and formed. Some software is more accurate than others on how it does this.
The same issue may present itself in Devanagari script:

Again, on the right you can see the composing is not working correctly. If you’re really unlucky, for the Arabic version you may be seeing this:
![]()
This comes about because Arabic is written right-to-left. English, on the other hand, is written left-to-right. However, this corrupted example of Arabic has been written left-to-right — .siht ekil etorw I if sa
Ordering problems may also arise when fully blown domain names are used. Imagine a domain like maps.google.com. Now imagine it showing up as com.google.maps. That’s confusing, but imagine the confusion of google.com.maps, or worst of all, as google.com.spam. These are some of the variants that have shown when right-to-left ordering issues appear due to software problems. (More on this issue is in this presentation from the Israel ccTLD registry.)
Apart from the visual display issue, there can also be issues simply in transmitting these domains in communications. The DNS has been carefully upgraded to support these new domains, but that doesn’t mean you will get a consistent experience in other areas. In a discussion on these new test domains on an Internet mailing list, one person found they were showing like this:

This is because the encoding in the email is incorrect. Generally speaking, to fully express all the possible IDNs you need to use an encoding like UTF-8. However, ISO 8859-1 is often the default on many mail programs for users of English and other Western European languages. The result of viewing UTF-8 encoded labels in ISO 8859-1 results in the undecipherable letter soup you see above. If you’ve ever received foreign spam that just looked like a list of random letters, this is probably why.
This is just touching on the number of problems that can express themselves when dealing with the world’s languages and scripts. With the release of the evaluative top-level domains, it will provide additional opportunity to identify these types of problems, and work with software vendors and other parties to help improve their applications so these issues will no longer occur.
