Représenter des langues multiples et des scripts dans la racine de l'Internet
TLa Société pour l'attribution des noms de domaine et des numéros sur Internet (ICANN) gère la zone racine pour l'Internet mondial. La zone racine contient la liste officielle et l'enregistrement de tous les domaines de premier niveau (TLD). Depuis le début de l'Internet, seul un sous-ensemble de TLD en script latin a été autorisé dans la zone racine. Cela est dû à l'origine et à la conception héritée du système des noms de domaine (DNS). Le DNS a été initialement conçu pour gérer les scripts latins au format ASCII.1 En 2010 une solution technique a été mise en place pour permettre l'introduction de noms de domaine en plusieurs langues et scripts au premier niveau du DNS sans déstabiliser l'Internet.
Il existe quatre types de domaines de premier niveau qui sont pertinents pour les utilisateurs d'Internet : les domaines de premier niveau géographique (ccTLD), les domaines génériques de premier niveau (gTLD), les domaines de premier niveau géographique internationalisés (gTLD IDN) et les domaines génériques de premier niveau internationalisés (ccTLD IDN). Les TLD qui entrent dans la catégorie des codes géographiques représentent les noms officiels des pays et territoires conformément à la norme internationale ISO3166-1.2 Les TLD génériques se rapportent à des noms ou à la représentation des noms autres que ceux associés aux noms officiels de pays et de territoires. Les noms de domaine internationalisés (IDN) se rapportent à des noms de domaine dans plusieurs scripts et langues qui vont au-delà du jeu de caractères ASCII original.3 Voir l'encadré 1 pour des exemples de domaines de premier niveau par catégorie.
Encadré 1 – Étiquettes de noms de domaine et exemples de domaines de premier niveau par catégorie
Que sont les étiquettes des noms de domaine ?
Les noms de domaine sont organisés selon une hiérarchie d'étiquettes depuis le niveau le plus bas au plus haut niveau dans le système des noms de domaine (DNS). Exemple : en.wikipedia.org. Ici, « org » est une étiquette de nom de domaine au plus haut niveau ou premier niveau, « wikipedia » est une étiquette de nom de domaine de second niveau, et « en » est une étiquette de nom de domaine au troisième niveau, le plus bas.
Exemples de domaines de premier niveau (TLD) par catégorie
ccTLD |
.de (Allemagne) | .et (Éthiopie) | .my (Malaysie) | .pr (Puerto Rico) |
IDN ccTLD |
مصر (Egypte) | 中国 (Chine) | भारत (Inde) | ไทย (Thaïlande) |
gTLD |
.com | .org | .ngo | .guru | .bank | .email | .organic | .photography |
IDN gTLD |
みんな (tout le monde) | дети (enfants) | संगठन (organization) | 世界 (monde) | بازار (bazar) | 삼성 (Samsung) | vermögensberatung (avis financier) | คอม, (com) |
Domaines de premier niveau géographique internationalisés
Ce n'est qu'en 2010 que les pays ont eu la possibilité d'avoir leurs TLD géographiques représentés dans des scripts autres que le script latin. L'ICANN a créé la procédure accélérée d'établissement de noms de domaine internationalisés pour des extensions de premier niveau géographique (ccTLD IDN) pour que les pays aient leurs TLD géographiques ou de noms de pays dans les scripts locaux qui reflètent leur base linguistique.
La première série de ccTLD IDN insérée dans la zone racine était en arabe.4 Vers la moitié de 2015, l'ICANN a approuvé 47 ccTLD IDN qui couvrent 15 scripts et 24 langues.5 Les deux-tiers de ces scripts appartiennent à la région Asie Pacifique. La plus forte demande pour les ccTLD IDN a été pour l'écriture arabe (38 %), suivie du cyrillique (14,9 %) et du han (14,9 %), du tamoul (6,4 %) et du Bangla/Bengali (4,3 %) – Voir la figure 1 pour une décomposition de toutes les candidatures aux ccTLD IDN. L'Inde a la particularité d'avoir le plus grand nombre de scripts (sept en tout) représentant le nom de son pays, qui reflètent sa diversité linguistique nationale.
Figure 1: décomposition des candidatures aux ccTLD IDN
Script demandé |
Nombre de candidatures |
Arabe |
18 |
Cyrillique |
7 |
Han (Chinois) |
7 |
Tamil |
3 |
Bangla/Bengali |
2 |
Arménien |
1 |
Devanagari |
1 |
Géorgien |
1 |
Grec |
1 |
Gujarati |
1 |
Gurmukhi |
1 |
Hangeul |
1 |
Singhalais |
1 |
Télougou |
1 |
Thaï |
1 |
Total |
47 |
TLD génériques internationalisés
Le déploiement des TLD génériques d'IDN est toujours en cours et exige la participation des communautés de scripts du monde entier. Chaque communauté linguistique qui veut avoir son script effectivement représenté dans les efforts qui déterminent les TLD qui seraient autorisés dans la zone racine devrait s'engager dans le travail des panels de génération de scripts. L'engagement peut avoir différentes modalités, à savoir, former, soutenir et faciliter les panels, devenir des membres du panel et fournir sa collaboration ou la rétroaction aux panels pendant l'appel à consultation publique de l'ICANN. La fonction des panels de génération de scripts selon le modèle de collaboration ascendant et multipartite utilisé par l'ICANN et d'autres organisations de l'Internet. Dans un souci d'efficacité, les panels doivent inclure des experts en politique, DNS, Unicode, IDN, des experts linguistiques et d'opération des noms de domaine. Là où l'expertise ne serait pas disponible, une aide peut être demandée à l'ICANN.
Les panels de génération de scripts sont responsables de l'élaboration de propositions qui déterminent les règles de génération d'étiquettes (LGR) spécifiques à un script pour la zone racine. Ces propositions sont élaborées en fonction de l'expertise et les exigences pour l'utilisation d'un script en particulier dans les étiquettes TLD IDN. Entre autres, le travail consiste à passer par tous les caractères d'un script et identifier quel caractère serait autorisée pour les étiquettes TLD, lequel ne le serait pas, et quelles seraient les règles applicables pour déterminer les étiquettes valides et leurs variantes (le cas échéant). Comme les panels de génération doivent couvrir tous les répertoires des caractères du script ainsi que leurs points de code Unicode correspondants, le travail exige des efforts considérables des volontaires issus des communautés de scripts.
Actuellement, il y a environ 20 communautés de scripts qui travaillent activement au développement de Règles de génération d'étiquettes (LGR) pour la zone racine. La gamme de scripts incluent les scripts arabe, arménien, bengali, chinois, cyrillique, devanagari, gujarati, gurmukhi, japonais, kannada, khmer, coréen, latin, malayalam, oriya, tamoul et télougou. Le gros du travail se concentre sur les scripts de la région Asie-Pacifique. Ce n'est pas surprenant compte tenu que près de la moitié des 3 milliards des utilisateurs de l'Internet actuels se trouvent dans cette région. Le prochain milliard d'utilisateurs de l'Internet devraient entrer en ligne vers l'an 2020. La majorité viendra aussi de la région Asie-Pacifique. La demande pour l'utilisation d'Internet dans les scripts et langues locaux existe. En Asie, les gouvernements ont contribué à initier et faciliter le lancement des panels de génération de scripts. Ces gouvernements comprennent l'importance de l'accessibilité à l'Internet et de la facilité d'utilisation dans des scripts locaux pour leur population.
Les panels de génération qui mettent l'accent sur un script qui est partagé entre plusieurs langues auront besoin de davantage de temps pour achever leur travail si on les compare aux panels qui ont affaire une seule langue. Par exemple, le panel de génération arménien a pu compléter sa proposition sur un script utilisé par la langue arménienne en seulement six mois. Par contre, le panel de génération arabe a pris environ 20 mois pour compléter son travail. Une période plus longue s'est avérée nécessaire car le script arabe est utilisé par plus de 50 langues à travers l'Afrique, le Moyen-Orient et l'Asie (plus précisément l'Asie occidentale, l'Asie du Sud et l'Asie du sud-est). Le panel de génération arabe a été un pionnier dans le projet de règles de génération d'étiquettes de la zone racine de deux points de vue. Il a été le premier à s'organiser pour le travail et son expérience a abouti à la méthodologie et aux modèles qui sont utilisés pour guider le travail des panels de génération ultérieurs.
Les propositions des panels de génération arabe et arménien sont maintenant complètes et ont été publiées par l'ICANN pour la révision et les commentaires du public – Voir l'encadré 2 pour des liens vers les appels à consultation publique. Les communautés des langues concernées sont fortement encouragées à répondre et fournir la rétroaction afin de s'assurer que les répertoires de scripts pour la zone racine abordent les besoins linguistiques des utilisateurs de l'Internet.
Encadré 2 – Appel à consultation publique de l'ICANN sur les propositions de règles de génération d'étiquettes du panel de génération de scripts
Proposition de règles de génération d'étiquettes de la zone racine pour le script arabe - https://www.icann.org/public-comments/arabic-lgr-proposal-2015-08-24-en.
(Date de clôture : 16 octobre 2015)
Proposition de règles de génération d'étiquettes de la zone racine pour le script arménien - https://www.icann.org/public-comments/proposal-armenian-lgr-2015-07-22-en.
(Date de clôture : 31 août 2015)
La figure 2 donne un aperçu de tous les caractères que le panel de génération arabe propose pour former des TLD IDN en script arabe. Il identifie quels sont les caractères proposés pour être inclus ou exclus qui seraient applicables à toutes les langues qui utilisent le script arabe.
Figure 2 – Tables Unicode pertinentes avec des caractères arabes proposées par le panel de génération arabe (GP) pour les règles de génération d'étiquettes de la zone racine (LGR)
Jaune – proposé pour les règles de génération d'étiquettes de la zone racine par le GP arabe
Bleu - exclu par le GP arabe
Rose – exclu du répertoire maximal initial (MSR)
Blanc – refusé par IDNA2008 par l'IETF
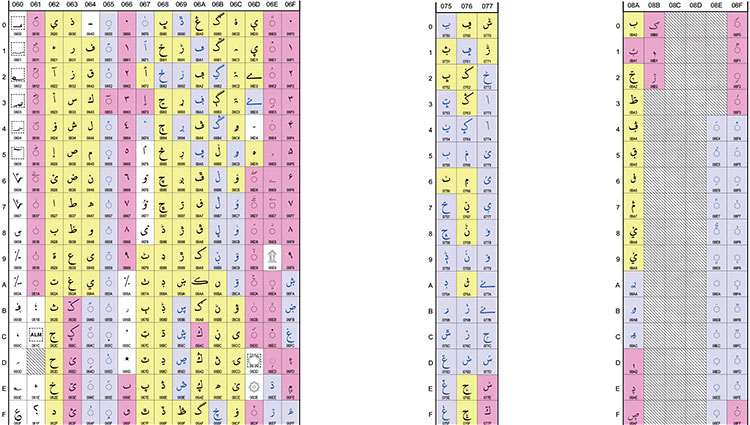
L'encadré 3 montre le cas d'une écriture arabe localisée en Asie du sud-est (c.-à-d. Jawi). Le cas identifie les caractères Jawi qui sont proposés pour être exclus des TLD IDN.
Encadré 3 - Le cas du Jawi
Jawi (جاوي) est le nom localisé de l'écriture arabe utilisé dans les langues de l'Asie du sud-est. Ces langues sont les Acehnese, Banjarese, Malay, Minangkabau et Tausug. Les pays qui utilisent les enregistrements du Jawi incluent le Brunei, l'Indonésie,la Malaisie, Singapour et la Thaïlande. Des variantes du Jawi se trouvent également dans d'autres pays de la sous-région. Le Jawi était autrefois un script dominant au sud-est asiatique. Son utilisation a été affectée par l'adoption généralisée de l'alphabet latin. À présent, le Jawi conserve un statut officiel au Brunei et la Malaisie. Brunei a adopté le Jawi comme l'un de ses deux scripts officiels tandis que la Malaisie l'utilise comme un script alternatif qui est généralement réservé à des fins religieuses, culturelles, académiques et administratives. La candidature réussie de la Malaisie pour son code de pays TLD en script arabe (.مليسيا) est révélateur du statut officiel du Jawi dans le pays. Le panel de génération arabe a factorisé le Jawi et le malais lors de sa révision du script pour déterminer les règles de génération d'étiquettes pour la zone racine. Les principaux documents liés au Jawi de la Malaisie révèle près de 50 caractères (et les points de code Unicode correspondants) d'intérêt dans le script arabe.6 La quasi-totalité de ces caractères a été incluse dans la proposition des règles de génération d'étiquettes du panel arabe pour la zone racine. Trois caractères ont été proposés pour leur exclusion (voir tableau ci-dessous).
Tableau des caractères Jawi proposés pour exclusion des TLD IDN pour le script arabe
Caractère |
Point de code unique |
Nom et propriétés du point de code |
Nom Jawi en caractère codé7 |
[Exclu par] - Fondement |
۲ |
06F2 |
CHIFFRE ARABE-HINDI ÉTENDU DEUX |
CHIFFRE ARABE-HINDI ÉTENDU DEUX |
[IETF]8 – Les chiffres ne sont pas permis dans les étiquettes TLD. |
ڬ |
06AC |
LETTRE ARABE KAF AVEC UN POINT AU DESSUS |
GAF |
[Panel d'intégration]9 - Obsolète Malais-Jawi. Utiliser ݢ (U+0762) à sa place. |
ء |
AUCUN |
AUCUN |
HAMZA ARABE TROIS QUARTS |
[Panel de génération arabe] - Pas d'encodage Unicode et donc non admissible pour considération. |
Le script Jawi et les communautés linguistiques associées en Asie du sud-est sont invitées à examiner la proposition et fournir une rétroaction à travers le processus de commentaires publics de l'ICANN qui sera ouvert jusqu'au 16 octobre 2015 (https://www.icann.org/public-comments/arabic-lgr-proposal-2015-08-24-en).
Restrictions techniques à la diversité linguistique dans la racine
Le travail des panels de génération de scripts est encourageant et permet de s'approcher de plus en plus de la vision de l'ICANN : « Un monde, un Internet ». Au sein de l'ICANN il y a la conviction généralisée que les IDN augmenteront l'utilisation de l'Internet de la part de la majorité de la population mondiale et la communauté de l'ICANN a fortement soutenu le déploiement des IDN. Cela a conduit à la mise en place du programme IDN, qui a supporté la procédure accélérée ccTLD IDN qui a habilité les ccTLD IDN et le projet de règles de génération d'étiquettes de la zone racine qui a habilité les TLD IDN.
Dans un monde avec plus de 7 milliards d'habitants, plus de 7000 langues vivantes et de nombreux systèmes d'écriture ou de scripts, un Internet capable de servir le monde devrait être linguistiquement diversifié.10 Parce que la zone racine est un espace global partagé, les ajouts de TLD sont limités en vertu des principes pour l'opération de zone proposés par le Groupe de travail de génie Internet et les politiques de l'ICANN pour la sécurité et la stabilité. La procédure adoptée par l'ICANN pour développer et maintenir les règles de génération d'étiquettes pour la zone racine restreint les ajouts à la zone racine pour « les système d'écriture où il y a un intérêt évident ».11 Les communautés linguistiques qui sont actives sur Internet et qui ont un intérêt évident pour que leur script entre dans la zone racine sont fortement encouragées à s'engager dans le processus de règles de génération d'étiquettes de leur script.
Le défi de l'acceptation universelle
Malgré tous les efforts déployés par l'ICANN et sa communauté de parties prenantes, un obstacle majeur entrave la création d'un Internet multilingue : l'acceptation universelle. Les domaines de premier niveau ont évolué depuis leur introduction à l'échelle mondiale et ils continueront d'évoluer avec l'expansion future du programme des nouveaux TLD génériques de l'ICANN.12 Certains services internet et certaines applications logicielles n'ont pas suivi cette évolution. Cela fait que les TLD ne soient pas utilisables et essentiellement bloquent l'accès des utilisateurs aux sites Web, à la messagerie électronique et à d'autres applications - Voir l'encadré 4 pour savoir comment les noms de domaine sont importants pour les utilisateurs de l'Internet.
Les enjeux de l'« Acceptation universelle » comprennent les services Internet et les applications logicielles n'acceptant pas les TLD écrits dans des scripts multilingues autres que le code ASCII, n'acceptant pas les noms TLD de plus de trois caractères et ne soutenant pas l'introduction des IDN ou des noms non-ASCII dans la messagerie électronique. Selon le groupe directeur sur l'acceptation universelle, les « fournisseurs de services et de logiciels ont historiquement ignoré ces problèmes, leur marché a été restreint ou ils ont eu peu d'encouragements règlementaires pour investir dans des solutions qui apporteraient une véritable interopérabilité aux plates-formes ou aux applications »13
Résoudre le problème de l'« Acceptation universelle » exige que les fournisseurs de services internet et les développeurs de logiciels soient à l'appui du principe que tous les noms de domaine et adresses électroniques doivent être acceptés, stockés, traités et affichés d'une manière cohérente et efficace. Pour prendre en charge les utilisateurs d'Internet dans le monde entier, les TLD doivent être utilisables dans les applications indépendamment de leur script, leur longueur ou leur nouveauté. Si ce défi de l'« Acceptation universelle » peut être surmonté avec plus de soutien aux contenus locaux dans le monde entier, nous serions en mesure d'avoir un Internet multilingue.
Encadré 4 – Pertinence des noms de domaine pour les utilisateurs
Comment les noms de domaine sont-ils pertinents aux utilisateurs de l'Internet ?
Les ressources Internet sont traitées numériquement. Les noms de domaine rendent l'accès plus facile à ces ressources sans avoir à mémoriser des numéros. La plupart des utilisateurs ne serait ni en mesure d'accéder à l'Internet, ses services et applications ni de les utiliser sans les noms de domaine. Ces applications comprennent la toile d'araignée mondiale et la messagerie électronique. Il faut se rappeler que les adresses e-mail contiennent des noms de domaine après le symbole « @ ». Normalement, les utilisateurs finaux de l'Internet utilisent les noms de domaine pour accéder aux navigateurs, au courrier électronique et aux applications mobiles. Ils utilisent également des noms de domaine lorsqu'ils créent des comptes en ligne pour les services Internet. La plupart des utilisateurs finaux utilisent les noms de domaine pour accéder aux contenus publiés par autrui. Quelques-uns enregistrent aussi des noms de domaine pour publier leur propre information à travers des sites Web
Rinalia Abdul Rahim est membre du panel de génération arabe pour les règles de génération d'étiquettes de la zone racine et de l'équipe spéciale sur les IDN arabes. Elle est l'ancienne co-présidente du groupe de travail l'At-Large sur les IDN ciblé sur les questions d'intérêt pour les utilisateurs individuels d'Internet du monde entier en matière de noms de domaine internationalisés. Elle est également membre du Conseil d'administration de l'ICANN et du groupe de travail du Conseil d'administration de l'ICANN sur les IDN et les variantes.
1 ASCII signifie Code standard américain pour l'échange d'information.
2 http://www.iso.org/iso/countrycodes/countrycodes
3 L'ensemble original de caractères ASCII autorisés dans les noms de domaine inclut les lettres de a à z, les chiffres et le trait d'union. Les noms de domaine de premier niveau ont une restriction spéciale car ils peuvent contenir des lettres mais pas des chiffres ou des traits d'union.
4 https://www.icann.org/news/announcement-2010-05-05-en
5 https://www.icann.org/resources/pages/string-evaluation-completion-2014-02-19-en.
6 Dewan Bahasa dan Pustaka, Daftar Kata Bahasa Melayu-Rumi-Sebutan Jawi (2001); MYNIC/.MY Domain Registry, tableau de langue Jawi soumis au référentiel de l'IANA (2009); MYNIC/.MY Domain Registry, Rapport pour le nom de domaine internationalisé de la Malaisie : questions de langue Jawi, Version 1.0 (2009) ; Standards Malaysia, normes de la Malaisie sur le jeu de caractères codés TI-Jawi pour l'échange d'informations (2012). (2012).
7 Standards Malaysia, normes de la Malaisie sur le jeu de caractères codés TI-Jawi pour l'échange d'informations (2012).
8 Groupe de travail de génie Internet (IETF) RFC1123 et RFC6912
9 Panel d'intégration chargé de l'établissement de règles de génération d'étiquettes d'IDN dans la zone racine, MSR-1-Annotated-non-CJK-Tables-20140606 pages 32-38 (https://www.icann.org/en/system/files/files/msr-non-cjk-06jun14-en.pdf [PDF, 1.86 MB]).
10 https://www.ethnologue.com/enterprise-faq/how-many-languages-world-are-unwritten
11 https://www.icann.org/en/system/files/files/draft-lgr-procedure-20mar13-en.pdf [PDF, 1.39 MB]
12 Voir http://newgtlds.icann.org/en/program-status/delegated-strings pour une liste déroulante des TLD génériques qui sont sont délégués dans la racine.
13 https://www.icann.org/resources/pages/universal-acceptance-2012-02-25-en